
Gas Turbine Emission Prediction
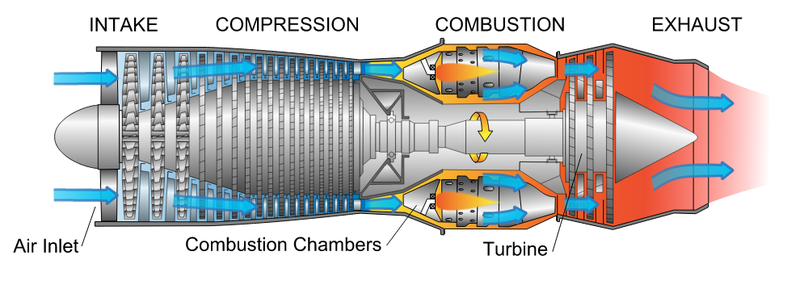
Recently, I worked with a dataset from a gas turbine located in Turkey’s northwestern region. This dataset was generated in 2015 by the Center for Machine Learning and Intelligent Systems (doi:10.3906/elk-1807-87). More specifically, it consists of 7384 instances from 11 sensors.
The purpose of the study was to analyze CO and NOx emissions, and the data range includes gas turbine parameters and ambient variables. I created three models for gas turbine emission prediction:
1. Linear regression
2. Random forest
3. XGBRegressor
How it works?
A) Data preprocessing
The histogram diagram for each variable to check normality is:

And to check the outliers, we have:

The scatter plots for CO variable are:


And the heatmap plots are:

I use these libraries for classification of a dataset of Gas turbine:
seaborn, pandas, TensorFlow, Numpy and matplotlib.
AP: Ambient pressure
AH: Ambient humidity
AFDP: Air filter difference pressure
GTEP: Gas turbine exhaust pressure
TIT: Turbine inlet temperature
TAT: Turbine after temperature
CDP: Compressor discharge pressure
TEY: Turbine energy yield
CO: Carbon monoxide
NOx: Nitrogen oxides